Blog
Xoriant Open Source Contribution to Apache Arrow - JDBC Adapter
Blog
Xoriant Open Source Contribution to Apache Arrow - JDBC Adapter




Abstract
Xoriant recently contributed to an Open Source community project - Apache Arrow. Xoriant team developed a feature called JDBC Adapter. This new feature is now available as a part of the latest 0.10.0 release of Apache Arrow.
This blog will talk about Apache Arrow, its objectives, followed by details about Xoriant’s contribution to Apache Arrow for a new feature - JDBC Adapter.
Apache Arrow - High-Level Overview
Data Format Conversion Problem
Big data ecosystem has multiple Open Source projects. There are data storage frameworks such as Apache Cassandra, Apache Kudu, Apache HBase along with data formats such as Apache Parquet. At the same time, there are multiple data processing frameworks or tools such as Apache Spark, Python Pandas, Apache Drill and Apache Impala.
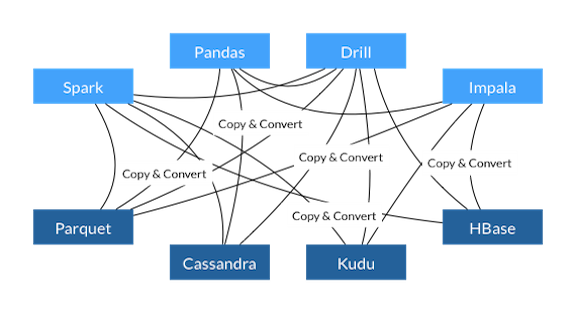 Figure 1: Multiple Data Formats and Conversions (Ref. https://arrow.apache.org/)
Figure 1: Multiple Data Formats and Conversions (Ref. https://arrow.apache.org/)
As shown above, it happens that all the mentioned storage and processing frameworks use their own internal data formats as well as on-disk storage formats. For a given data pipeline or data analytics exploration, data constantly moves between the storage layer and in-memory processing layer. During this data movement, data objects get serialized and de-serialized based on the varying data formats of the underlying source and destination systems. This data serialization and de-serialization adds a huge performance penalty in any data exploration or data analytics pipeline.
What is Apache Arrow?
Apache Arrow is a cross-language development platform for in-memory data storage and processing. Apache Arrow specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. Arrow acts as a new high-performance interface between various systems.
![]() Figure 2: Arrow as Common Data Format Layer (Ref. https://arrow.apache.org)
Figure 2: Arrow as Common Data Format Layer (Ref. https://arrow.apache.org)
It is envisioned that the data storage as well as data processing components in the data analytics pipeline, will use the same in-memory data format as defined by Apache Arrow and hence get rid of performance penalty caused by continuous data serialization and de-serialization.
What it is not?
It is not a technology that anyone will be directly using. Jacques Nadeau, who is project’s vice president, says that it is not a storage or processing engine but a technology that can be embedded within other projects as an embeddable accelerator and a way of moving data between systems. He articulates that it is a technology that will enhance the technologies that we already use.
Some interesting facts
Apache Arrow is a collaborative project across 13 other Open Source projects, including Apache Drill, Apache Cassandra, Apache Hadoop and Apache Spark. Interestingly, Apache Arrow became a direct top-level project straightaway – no incubation period like other Apache projects. It was initially seeded by code from Apache Drill.
JDBC Adapter for Apache Arrow
Purpose of the JDBC Adapter is to enable data pipeline tools to query data sitting inside JDBC compliant relational databases and get the JDBC objects converted to Apache Arrow objects/structures. The upstream data pipeline tools can then work with Arrow objects/structures with performance benefits. This adapter effectively converts a row-wise data objects from the relational database table into an Arrow columnar format vector. The adapter API generates two artifacts – Arrow Vector Schema and Arrow Columnar Vector Format objects.
![]() Figure 3: JDBC Adapter for Arrow (Ref. https://arrow.apache.org/)
Figure 3: JDBC Adapter for Arrow (Ref. https://arrow.apache.org/)
The Xoriant team contributed to Apache Arrow for JDBC Adapter feature and completely developed and tested it.
JDBC Data Types to Arrow Data Type Conversion
Following is the type conversion table between JDBC Data Types and Arrow Data Types,
![]()
Types - java.sql.Types
Calendar – java.util.Calendar
ArrowType - org.apache.arrow.vector.types.pojo.ArrowType
SINGLE – enum org.apache.arrow.vector.types.FloatingPointPrecision.SINGLE
DOUBLE – enum org.apache.arrow.vector.types.FloatingPointPrecision.DOUBLE
DateUnit – enum org.apache.arrow.vector.types.DateUnit
TimeUnit – enum org.apache.arrow.vector.types.TimeUnit
Adapter Components
The JDBC Adapter has following two components
- JDBC to Arrow API
- JDBC to Arrow Utils
JDBC to Arrow API
This component acts as a façade for the adapter utility.
JDBC to Arrow Utils
This component contains the necessary utility code that essentially implements the following,
- Executes the JDBC query
- Uses JDBC ResultSetMetaData object from the query results, and defines the Arrow Schema
- Traverses the JDBC ResultSet and creates the columnar format Arrow Vector objects
The source code is available at - Github.com
Corresponding JIRA is - Issues.apache.org
Arrow JDBC Adapter Use Cases
Improving non-JVM environments
As per Dremio blog on Arrow's origin and history – one of the important aspects of Arrow is to bridge two different worlds of processing, for example, JVM-based environments and non-JVM environments, such as Python and C++. Apache Arrow makes it easier for exchanging data between these various environments. One particular use case for Python / Pandas environment where we can leverage Arrow JDBC Adapter is depicted below,
![]()
Figure 4: Using Arrow JDBC Adapter in Python / Pandas environment
If Python / Pandas environment wants to fetch data from Relational Database, it needs to use ODBC or Python-native drivers, which are very poor in performance as compared to JDBC drivers. But the moment you introduce JDBC driver, you pay the penalty of high cost of converting JDBC objects to Python objects and then to Arrow objects.
By using the Arrow JDBC Adapter, we can now convert JDBC objects directly to Arrow objects without the serialization overhead.
References
Dremio.com/origin-history-of-apache-arrow
Apache Arrow 0.10.0 Release Changelog: Arrow.apache.org
Apache Arrow 0.10.0 Release Blog Post: Arrow.apache.org










