
Blog
Natural Language Processing | Next Disruptive Technology Under AI - 2
Blog
Natural Language Processing | Next Disruptive Technology Under AI - 2




The first part of this blog focused on understanding NLP, its claim to fame, and applicability in today’s world. It also highlighted the NLP aspects, categories, and usage in applications.
The second part of the blog will entail real-world problem-solving application areas of NLP and the challenges encountered in its implementation.
The global Natural Language Processing (NLP) market size is growing tremendously. According to Fortune Business Insights, the NLP market value is expected to reach USD 80.68 billion by 2026, against USD 8.61 billion in 2018. Rising demand for big data, improved algorithms, and powerful computing are the contributing factors to the momentum increase in NLP market size.
NLP: Business Application Areas
- Customer service with chatbots: Today, in this competitive market, customer demands are increasing. Businesses are being flooded with customer queries. In order to meet customer expectations and ensure quick response time, organizations are introducing automated agents called Chatbots. These chatbots are developed to understand natural language and respond to the queries. With the growing popularity and convenience of using voice-based query understanding and reciprocation, soon, all the queries will be accepted and responded to via voice-based intelligent agents and GUI. In addition, we will witness UI becoming obsolete.

- Big data management: Currently, there is a humongous amount of unstructured data being generated through different channels. It has gradually become impossible to process this data without the usage of NLP technologies. The use of NLP technology makes it convenient to ask a simple question and receive information on any specific topic. This is comparatively easier than the manual process of sifting through massive chunks of data to find accurate information.
- Analysis of unstructured data: Given the nature of data, applying NLP helps harness and analyze unstructured data—video, audio, images, text, and other forms—to provide insights and promote smarter decision making. NLP can be used to understand the data represented by statistical charts, graphs, or financial reports and convert the same to natural language, making it comprehensible. Generating financial reports, legal documents, press releases, product descriptions, essays, and easy-to-understand weather forecasting reports are some of the common areas where natural language processing is widely used.

- Topic Discovery or Automatic Document Classification: Topic segmentation, recognition, and document classification are other capabilities of natural language processing. This implies an input data set and machine learning models with the capability to classify text into several topics. As is the case with other machine learning problems, this type of problem is also known to have two approaches, namely, unsupervised and supervised learning. While in the case of unsupervised learning algorithms, the training data used does not have output labels or simply put, the class to which each text corpus belongs. NLP algorithms are trained on relevant data meant for categorization and identification.
Topic Discovery or Automatic Document Classification involves using machine learning models to categorize and structure large volumes of text into meaningful topics. In educational applications, tools like an ai study guide maker can help automatically organize complex information into structured learning materials for better understanding.
Post this, when the trained supervised NLP algorithmic model is exposed to new input data, it would be able to indicate to what topic class the new text should belong. In NLP’s context, unsupervised algorithms, on the other hand, basically rely on machine learning clustering algorithms that can separate the text data into segment groups and then identify its class. The accuracy of the algorithm prediction depends on the volume of the available training data, the similarity between the new incoming text and the data of the trained algorithm.
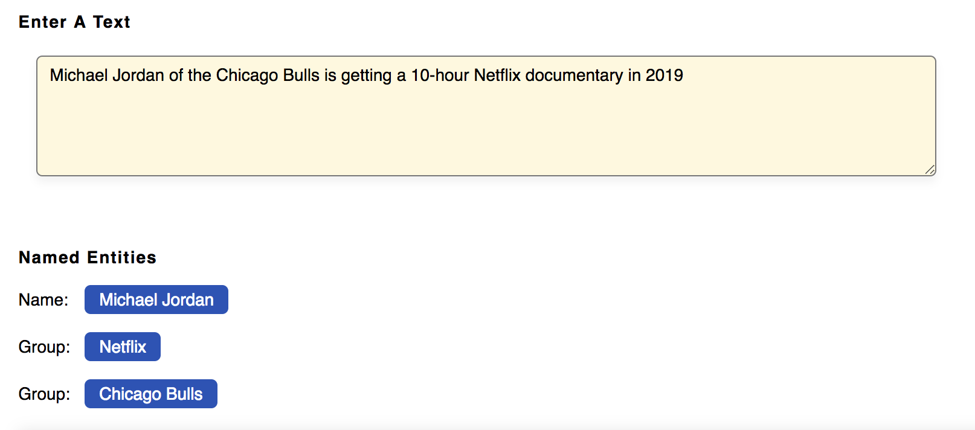
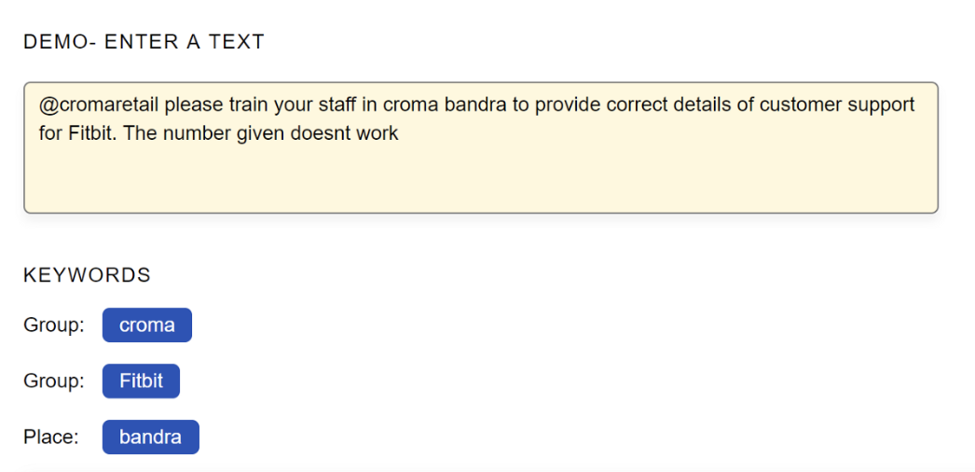
- Named Entity Recognition: Named Entity Recognition or NER which is also known as entity extraction, is the process involving the classification of named entities that are present in a text into pre-defined categories like “companies”, “locations”, “individuals”, “cities”, “organizations”, “dates”, “product terminologies”, etc. For example, Named Entity Recognition can automatically scan an entire article to give us insight into the major people, places or organizations discussed in the article. Once the relevant tags for each article are known, it helps in the automatic categorization of the articles in defined hierarchies, enabling easy discovery and content understanding.
NLP Challenges:
Understanding Natural Human Language
Due to the variations in human languages, developing a system that understands and reads like a human has always been challenging. So, the task of natural language understanding is still an open problem. For instance, the word ‘book’ can be used as a verb or a noun. When written, “I want to book a ticket”, the word is used as a verb. However, when written, “I read the book”, it is used as a noun. By ascertaining the topic and the context, it is easier to understand what the word ‘book’ represents and the meaning it conveys in each of the above examples. But when it comes to machine, making sense of the word ‘book’ in each of these cases is still a daunting challenge. Though various inroads and progress has been made, making computers understand complex scenarios, it still requires considerable effort.
Speech Recognition
Speech recognition or the task of converting speech to text is an extremely difficult problem. Enabling machines to detect the different accents accurately, slang words or different languages that are spoken by humans still needs progress and better expertise. For example, the inherent problem may be in being able to interpret the spoken words that sound similar, for instance, ‘youth in Asia’ or as ‘euthanasia’. Similarly, when trying to interpret similar-sounding spoken words, for instance, ‘recognize speech’ or as ‘wreck a nice beach’.
Multiple Lingos in Machine Translation
Another challenge or limitation, as seen in machine translation (translating from one language to another using machines) is that, since there are tens of thousands of words in every language and many different meanings to thousands of words based on the used word’s context, it is virtually impossible for a computer to understand the context, especially in complex scenarios. Moreover, as machines are unable to understand emotions, non-verbal communication and culture, which has a significant influence in the context of the language, the quality of the translation will always be an inherent problem in machine translation. Machine translation helps us by understanding the language, but understanding the different meanings, lingo, and identifying cultural language peculiarities, is still a far-fetched dream.
The Evolution of NLP
Currently, NLP based voice assistants or Chatbots can comprehend and simulate only familiar behavior. So, if they happen to encounter queries that contain concepts never heard of, they will fail to provide a satisfactory answer. The current endeavor is to make these voice assistants more intelligent, to establish seamless communication and become adept at performing more complex tasks.
Unlike in the past wherein the Google search engine performed search by simply matching the keywords in the search query, currently, it has refurbished it’s behind the scenes algorithms to conduct what is known as semantic search. Here the search engine is more focused upon retrieving answers rather than just results. By using a combination of search based on the user intent (what is the user actually searching for?), user context (why is he searching?), with the user location and his past search history, the Google search engine is now able to retrieve more accurate, relevant, and customized search results. This major achievement or milestone has been possible only through NLP.
Up until recently, businesses were at a loss to harness, understand and gain insights from the vast unstructured data being generated in the form of natural human language. With over 80% data in unstructured form, the advances made in NLP has made it possible to analyze and learn from data from different sources and formats.
Because of the inherent vagueness and ambiguity that frequently appears in human languages, it was earlier difficult or impossible for machine learning algorithms to interpret and understand them. However, with Deep Learning, Artificial Intelligence, and the continuous improvements and advancements, these feats are now possible.
At Xoriant, NLP-based business applications have been successfully implemented for customers. We bring three decades of next-generation technology expertise, strong technology partnerships and high-performance teams who can deliver stupendous NLP based solutions and applications for your business requirements. In addition, our inhouse developed frameworks help organizations transform unstructured text into usable insights. With salient features and benefits, they have been practically used in various customer use case scenarios such as reviewing unstructured documents, risk identification, regulatory compliance.
Talk to our experts now to know more Xoriant’s natural language processing capabilities and experience a seamless NLP implementation!
References










