
Blog
Real-time Access to Hadoop Based Data Lake




Today, big organizations are finding it increasingly difficult to store the exponentially growing data and access it for quick decision making. So, Data Storage and Faster Data Analysis are the two biggest challenges faced by today’s organizations.
To tackle these issues, we will look at Hadoop, an established Big Data technology and also few new-age technologies supporting MPP (Massively Parallel Processing) – SQL namely Cloudera-Impala, Apache-Drill and Facebook-Presto-DB.
Introduction
Organizations today generate huge amount of data which could be related to financial transactions, purchase transactions, social media, IP etc. This data is structured as well as semi-structured or completely unstructured. In short, data is a growing beast. Organizations want to tame this beast by storing more and more data and mine it for decision making, predictive analysis etc., in order to improve their top-line as well as bottom-line.
Historically, most of the organizations have been using Enterprise Data Warehouse (EDW) technologies to store and analyze the vast amount of data that they have. Underneath, EDW uses traditional database technologies such as Relational Database Management Systems (RDBMS) along with SQL Engine for data processing and analytics. EDW technologies typically work on structured data sets and are used to perform variety of Extract, Transform and Load (ETL) operations before data analytics can be performed.
The limitations of EDWs are
- Handling unstructured data
- Handling huge data sets
- They are very expensive
Let’s look at Hadoop-based Data Lake and how it can solve all of these problems.
Hadoop-based Data Lake
Hadoop-based Data Lake is a massive, easily accessible data repository built using Hadoop. Hadoop uses Hadoop Distributed File System (HDFS) as underlying technology on top of commodity hardware allow to store unlimited amount of data of any format and type. HDFS-based Data Lake can also store unstructured, semi-structured or multi-structured data, for e.g. binary streams from sensors, image data, machine logs and even flat-files. One more advantage you get with Data Lake is data once stored can be accessed and processed in many different paradigms.
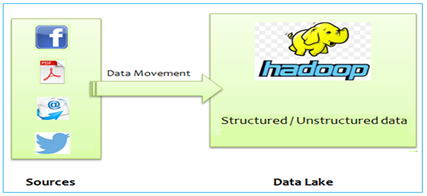
Hadoop-based Data Processing
Along with data storage, Hadoop’s Map-Reduce also provides a scalable parallel processing framework that can process large amount of data. Once data is transferred to Data Lake, for unstructured data there should be some Extract-Transform-Load (ETL) processes for transforming data to structured form and then made available for fast processing and analysis with Analytics and Reporting technologies that are mostly SQL-based.
Business scenario
Now, let’s look at a business scenario from Insurance Industry. Insurance industry generates huge amount of data (structured as well as unstructured). Insurance Companies generate huge data in different formats every day for different use cases such as - premium paid by customers, claim settled etc. which needs to be stored and analyzed for quick business decision making.
EXAMPLE use case
Here is a typical use case. A sales manager of Insurance Company may want to see a report of how much premium was paid and/or claims being settled during last financial quarter. He would want to fire this ad-hoc query on huge data sitting in the data storage and he would want to see the result of this query as quickly as possible.
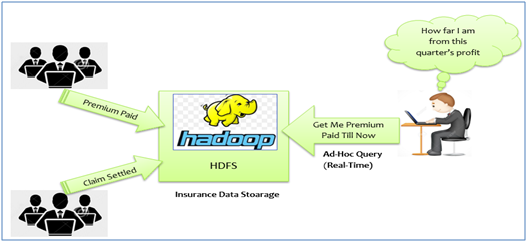
Proposed High-level Approach
The steps involved in solving this problem are:
- Data is transferred to Hadoop Data Lake.
- Preprocess the data as per the requirement which includes data cleansing and data validation.
- Make this data available to use with popular SQL-based BI and Analytics engines/products
Before moving forward to solution approach, let us consider few technologies which are available for performing data operations on huge amounts of data. There are database systems especially built to deal with huge amounts of data and they are called Massively Parallel Processing (MPP) databases. MPP is the approach in Grid Computing when all the separate nodes of the grid participate in the coordinated computations. MPP DBMSs are the database management systems built on top of this approach. In these systems each query you execute, gets split into a set of coordinated processes executed on different nodes of your MPP grid in parallel. Splitting the computations this way they get executed multiple times faster as compared to traditional SMP RDBMS systems.
Apache Hive
Apache Hive is an open-source data warehouse system built on top of Hadoop MapReduce framework for querying, summarization and analyzing large datasets. The Hive query language (HiveQL) is the primary data processing method on Apache Hive. It is best for batch processing large amount of data but it is not ideally suitable for transactional database or for real time access because of its slow response time.
Cloudera Impala
Cloudera Impala is a MPP query engine that runs on Apache Hadoop. It provides high-performance, low-latency SQL queries on data stored in Hadoop.
Spark SQL
Spark SQL is a Spark module for structured and semi-structured data processing. It provides a programming abstraction called Data Frames and can also act as distributed SQL query engine.
Apache Drill
Apache Drill is an open-source software framework that supports data-intensive distributed applications for interactive analysis of large-scale datasets. Drill is able to scale to 10,000 servers or more and to be able to process petabytes of data and trillions of records in seconds. Drill supports huge variety of NoSQL databases and file systems. A single query can join data from multiple datastores.
Presto DB
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Technologies’ COMPARISON
For this blog, we will be comparing the above mentioned technologies and will benchmark them against the problem statement as discussed above. The following sections talk about various fine tuning techniques we used for getting better performance, followed by cluster details and the results we obtained with various technologies for given problem statement.
Performance tuning techniques for Hive
Partitioning in Hive
Partitions are horizontal slices of data which allow larger sets of data to be separated into more manageable chunks.
Bucketing in Hive
Tables or partitions are sub-divided into buckets. Bucketing works based on the value of hash function of some column of a table. Bucketing can be done along with or without partitioning. Similar to partitioning, bucketed tables provide faster query response than non-bucketed table.
For our solution, at present we considered Parquet and ORC File formats for storing data in Hive table which are more efficient than others.
ORC File Format
The ORC (Optimized Row Columnar) file format provides a highly efficient way to store Hive data. ORC File improves performance when Hive is reading, writing, and processing data.
ORC file format stores metadata using Protocol Buffers which allows addition and removal of fields easily.
Parquet File Format
Parquet is an ecosystem wide columnar format for Hadoop. Parquet is built to support very efficient compression and encoding schemes. Parquet allows compression schemas to be specified on a per column level.
Solution
With our finalized approach we would be using following aspects to boost over-all data storage and query performance with Apache-Hive,
- Data partitioning
- Data bucketing
- ORC and Parquet file formats
Creation of Hive table and Loading data
We have created one external table that points to a specific location within HDFS.
There are two ways of inserting data into partition table.
Static Partition
In this mode, user has to know all values at the compile time that is - while loading data, user has to specify in which partition data will be stored.
Example:
LOAD DATA INPATH '/user/hadoop/InsuranceData/insurancedata.txt' INTO TABLE InsuranceDataORC PARTITION (state = 'CA');
In this example, insurancedata.txt file must contain data for ‘CA’ state and then data pertaining to State ‘CA’ will get loaded into its corresponding partition.
Dynamic Partition
In this mode, user need not care about values that will calculate at run time. We have used dynamic partition to load data into InsuranceDataORC from our external table InsuranceData. In order to achieve dynamic partition we need to do some configuration changes before loading data:
SET hive.exec.dynamic.partition = true;
SET hive.exec.dynamic.partition.mode=strict;
SET hive.enforce.bucketing=true;
Example:
Insert overwrite table PartitionTableName(columnName) select * from TableName;
This will load all data from Table to PartitionTable with partition on column and with buckets.
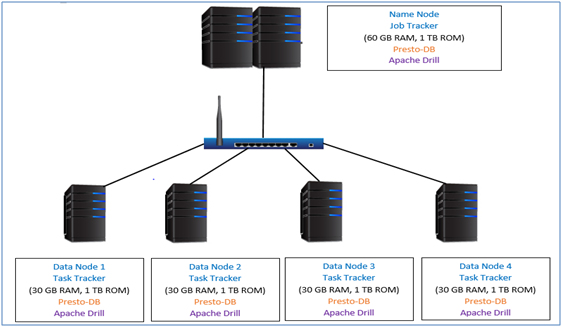
Cluster Configuration
We have five node Cloudera (5.4.3 Distro) cluster with aNamenode and 4 Data nodes. Namenode has 60 GB Memory and 1TB Storagewhile each data node has 30 GB Memory and 1 TB Storage.Apache Drill and PrestoDBcoordinator daemons are installed on Name Node while worker dameons are installed on all data node.
Performance comparison chart
We have compared HDFS files, Parquet files and ORC files with different query engine specified above.
Data set we used is of size 10 GB, which consists of 131 million records and 15.7 million customers.Data contains premium paid or claim by the customer (customer details, policy details, etc.).
First chart shows the comparison to get all information for a particular customer. And second chart shows aggregation data of all the states.
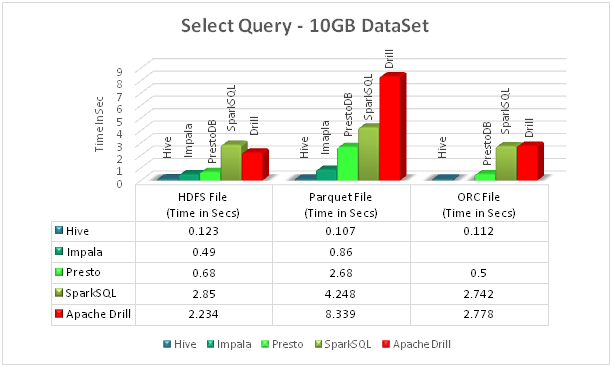
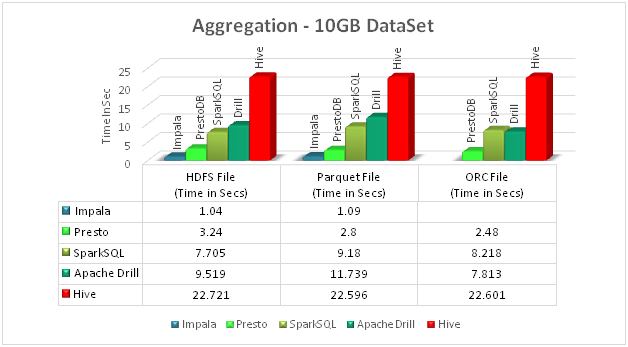
Note: Impala from Cloudera v 5.4.x does not support ORC file format.
References
Books
Hadoop - The Definitive Guide, 4th Edition
Web En.wikipedia.org
Cwiki.apache.org
Cwiki.apache.org-Hive/Parquet
En.wikipedia.org-Cloudera_Impala
Spark.apache.org
En.wikipedia.org-Apache_Drill





Get Started





